Overview
The lmeresampler package provides functionality to perform various bootstrap processes for nested linear mixed-effects (LMEs) models including parametric, residual, cases, wild, and REB bootstraps. This is particularly useful for models fit with relatively small data sets, where bootstrapping may yield more robust parameter estimates. This vignette seeks to inform users of:
how to bootstrap hierarchical linear models with
lmeresampler,what kinds of bootstraps are available and how they operate,
how to use the bootstrap output, and
extensions for both users and future developers of the package.
The Data
Examples of lmeresampler functions will use hierarchical linear models fit using jsp728, a data set containing information about 728 students (level-1) from 50 primary (elementary) schools in inner London (level-2) that were part of the Junior School Project (JSP). The data was collected by the University of Bristol Centre for Multilevel Modeling. For more information about the variables, see ?jsp728.
We will work with vcmodA for lme4, and vcmodB for nlme. Each of these two-level models predicts mathAge11 (the student’s math score at age 11) and contains the same 3 fixed effects: mathAge8 (the student’s math score at age 8), gender (the student’s gender), and class (the student’s father’s social class, a factor with two levels: manual and nonmanual). They also both have a random intercept for school. The models are as follows:
The Call
In order to perform the bootstrap, the user must call the bootstrap() function. The function contains several required parameters for the user to specify when making the call:
model: the LME model to be bootstrapped..f: a function that will compute the statistics of interest (for example, to have the bootstrap return the fixed effects estimates, specify.f = fixef).type: a character string specifying what type of bootstrap should be executed. Possible values are"parametric","residual","case","wild", or"reb". More information about each bootstraptypemay be found in the following sections.B: the number of bootstrap resamples to be performed.
Additional parameters are required by specific bootstrap methods:
resample: a logical vector specifying whether each level of the data set should be resampled in the cases bootstrap. The levels should be specified from the highest level (largest cluster) of the hierarchy to the lowest (observation-level). For example, for students within a school, specify the school level first, then the student level.reb_type: an integer value specifying what kind of REB (random effects block) bootstrap should be performed. More on what the differences between the REB bootstrap types are may be found in section 5 of this vignette.-
hccme: a character string specifying which heteroscedasticity consistent covariance matrix (HCCME) estimator to use in the Wild bootstrap. Current options include"hc2"and"hc3", the two estimators recommended by Modugno and Giannerini (2015).\[\begin{align} {\tt hc2} &: \tilde{\boldmath{v}}_i = {\rm diag} \left( \boldmath{I}_{n_i} - \boldmath{H}_i \right)^{-1/2} \circ \boldmath{r}_i\\ {\tt hc3} &: \tilde{\boldmath{v}}_i = {\rm diag} \left( \boldmath{I}_{n_i} - \boldmath{H}_i \right) \circ \boldmath{r}_i, \end{align}\]
where \(\boldmath{H}_i = \boldmath{X}_i \left(\boldmath{X}_i^\prime \boldmath{X}_i \right)^\prime \boldmath{X}_i^\prime\), the \(i\)th diagonal block of the orthogonal projection matrix, and \(\boldmath{r}_i\) is the vector of marginal residuals for group \(i\).
aux.dist: a character string specifying which auxillary distribution to use in the wild bootstrap. Current options include"mammen","rademacher","norm","webb", and"gamma", the distributions outlined by Roodman et al. (2019).
NEED TO UPDATE!! \[\begin{align} {\tt f1}: w_i &= \begin{cases} -(\sqrt{5} - 1)/2 & \text{ with probability } p=(\sqrt{5}+1) / (2 \sqrt{5})\\ (\sqrt{5} + 1)/2 & \text{ with probability } 1-p\\ \end{cases}\\ {\tt f2}: w_i &= \begin{cases} -1 & \text{ with probability } 0.5\\ 1 & \text{ with probability } 0.5,\\ \end{cases} \end{align}\]
1. The Parametric Bootstrap
The parametric bootstrap simulates bootstrap samples from the estimated distribution functions. That is, error terms and random effects are simulated from their estimated normal distributions and are combined into bootstrap samples via the fitted model equation.
Examples
# let's set .f = fixef to specify that we want only the fixed effects bootstrapped
# lme4
lmer_par_boot <- bootstrap(vcmodA, .f = fixef, type = "parametric", B = 100)
# nlme
lme_par_boot <- bootstrap(vcmodB, .f = fixef, type = "parametric", B = 100)Let’s also take a look at the structure of the lmeresamp objects returned by a bootstrap call.
bootstrap() output
Regardless of the type of bootstrap performed, the output of bootstrap() will be an lmeresamp object that is formatted as a list of length 13. Notice that some of the objects come from the call itself, while others are calculated for the user using the bootstrapped values.
names(lmer_par_boot)
#> [1] "observed" "model" ".f" "replicates" "stats"
#> [6] "B" "data" "seed" "type" "call"
#> [11] "message" "warning" "error"observed: the estimated values for the model parameters,model: the fitted model, formatted as the defaultmerModorlmeobject,.f: the function call,replicates: aB\(\times \ p\) data frame of bootstrap values for each of the \(p\) model parameters,stats: a tibble containing theobserved,rep.mean(bootstrap mean),se(bootstrap standard error), andbiasvalues for each model parameter,B: the number of bootstrap resamples performed,data: the data with which the model was fit,seed: a vector of randomly generated seeds that are used by the bootstrap,type: the type of bootstrap executed,call: the call tobootstrap()that the user,message: a list of lengthBgiving any messages generated during refitting. An entry will beNULLif no message was generated,warning: a list of lengthBgiving any warnings generated during refitting. An entry will beNULLif no message was generated, anderror: a list of lengthBgiving any errors generated during refitting. An entry will beNULLif no message was generated,
Notice that the elements message, warning, and error allow you to eliminate any iterations that might be problematic, such as if the model did not converge.
2. The Cases Bootstrap
The cases bootstrap is a fully nonparametric bootstrap that resamples the data with respect to the clusters in order to generate bootstrap samples. Depending on the nature of the data, the resampling can be done only for the higher-level cluster(s), only at the observation-level within a cluster, or at all levels. See Van der Leeden et al. (2008) for a nice discussion of this decision. The level(s) of the data that should be resampled may be specified using the resample parameter, which is a logical vector. When setting resample values, the user should make sure to first specify the highest level (largest cluster) of the hierarchy, then the lowest (observation-level). For example, for students within a school, the school level should be specified first, then the student level.
Examples
# lme4
# resample the schools, but not the students
lmer_case_boot <- bootstrap(vcmodA, .f = fixef, type = "case", B = 100, resample = c(TRUE, FALSE))
# nlme
# do not resample the schools, but resample the students
lme_cases_boot1 <- bootstrap(vcmodB, .f = fixef, type = "case", B = 100, resample = c(FALSE, TRUE))
# nlme
# resample both the schools and the students
lme_cases_boot2 <- bootstrap(vcmodB, .f = fixef, type = "case", B = 100, resample = c(TRUE, TRUE))3. The Residual Bootstrap
We implement the semi-parametric residual bootstrap algorithm proposed by Carpenter, Goldstein and Rasbash (2003). The algorithm is outlined below:
Obtain the parameter estimates from the fitted model and calculate the estimated error terms and EBLUPs.
Rescale the error terms and EBLUPs so that the empirical variance of these quantities is equal to estimated variance components from the model.
Sample independently with replacement from the rescaled estimated error terms and rescaled EBLUPs.
Obtain bootstrap samples by combining the samples via the fitted model equation.
Refit the model and extract the statistic(s) of interest.
Repeat steps 3-5
Btimes.
4. The Wild Bootstrap
The wild bootstrap exists for various types of models, but was first discussed in the context of hierarchical models by Modugno and Giannerini (2015). This bootstrap makes no distribution assumptions and allows for heteroskedasticity, which is often useful for economists. The heteroskedasticity is accounted for using the Heteroskedasticity Consistent Covariance Matrix Estimator (HCCME), and the two HCCMEs explored by Modugno and Giannerini (2015) were HC2 and HC3. These can be set in a call to bootstrap() using hccme = "hc2" or hccme = "hc3". The wild bootstrap also draws bootstrap samples for the errors from what is known as an auxiliary distribution.
FIX THIS!! The two versions of this discussed by Modugno and Giannerini (2015), F1 and F2, can be set in a bootstrap() call using aux.dist = "f1" or aux.dist = "f2". For more information on HCCMEs and the purpose and structure of the auxiliary distributions, please refer to Modugno and Giannerini (2015).
Examples
# lme4
lmer_wild_boot <- bootstrap(vcmodA, .f = fixef, type = "wild", hccme = "hc2", aux.dist = "mammen", B = 100)
lmer_wild_boot <- bootstrap(vcmodA, .f = fixef, type = "wild", hccme = "hc3", aux.dist = "mammen", B = 100)
# nlme
lme_wild_boot <- bootstrap(vcmodB, .f = fixef, type = "wild", hccme = "hc2", aux.dist = "rademacher", B = 100)
lme_wild_boot <- bootstrap(vcmodB, .f = fixef, type = "wild", hccme = "hc3", aux.dist = "rademacher", B = 100)5. The Random Effects Block (REB) Bootstrap
The random effects block (REB) bootstrap was outlined by Chambers and Chandra (2013) and has been developed for two-level nested linear mixed-effects (LME) models.
Consider a two-level LME of the form \(y = X \beta + Z b + \epsilon\).
The REB bootstrap algorithm (type = 0) is as follows:
-
Calculate the nonparametric residual quantities for the fitted model
- marginal residuals \(r = y - X\beta\)
- predicted random effects \(\tilde{b} = (Z^\prime Z)^{-1} Z^\prime r\)
- error terms \(\tilde{e} = r - Z \tilde{b}\)
Take a simple random sample with replacement of the groups and extract the corresponding elements of \(\tilde{b}\). Denote these resampled random effects as \(\bm{\tilde{b}}^*_i\).
Take a random sample, with replacement, of size \(g\) from the cluster (group) ids. For each sampled cluster, draw a random sample, with replacement, of size \(n_i\) from that cluster’s vector of error terms, \(\bm{\tilde{e}}_i\). Denote these resampled random effects as \(\bm{\tilde{e}}^*_i\).
Generate bootstrap samples via the fitted model equation \(y = X \widehat{\beta} + Z \tilde{b}^* + \tilde{e}^*\).
Refit the model and extract the statistic(s) of interest.
Repeat steps 2-4
Btimes.
Variation 1 (type = 1): The first variation of the REB bootstrap zero centers and rescales the residual quantities prior to resampling.
Variation 2 (type = 2): The second variation of the REB bootstrap scales the estimates and centers the bootstrap distributions (i.e., adjusts for bias) after REB bootstrapping.
6. Output Options
The newest version of lmeresampler comes equipped with summary(), print(), confint() and plot() methods for lmeresamp objects, all of which follow the syntax of generic summary(), print(), confint() and plot() functions. In order for these functions to operate as necessary, the output of the bootstrap() function has been updated to be an object of class lmeresamp. See the next sections for some examples.
The summary() function
The syntax of the summary() function is similar to the default. The object to be summarized must be the object returned by the bootstrap() call, an lmeresamp object.
Example
summary(lmer_reb_boot1)
#> Bootstrap type: reb1
#>
#> Number of resamples: 100
#>
#> term observed rep.mean se bias
#> 1 (Intercept) 14.1577509 14.1394345 0.7903203 -0.018316392
#> 2 mathAge8 0.6388895 0.6414264 0.0274476 0.002536938
#> 3 genderM -0.3571922 -0.3337360 0.3412967 0.023456237
#> 4 classnonmanual 0.7200815 0.7260191 0.4208054 0.005937571
#>
#> There were 0 messages, 0 warnings, and 0 errors.
The print() Function
The print() function in lmeresampler also follows the syntax of the default print() function. In lmeresampler, print() calls summary() to return information about the bootstrap() call. In addition, if the user would like to print confidence intervals for the object, setting ci = TRUE in print() will call the confint() function and set method = "all" and level = 0.95. If not all of the intervals are of interest or a different confidence level is required, it is recommended that the user directly call confint() on the bootstrap object.
Examples
print(lmer_reb_boot0)
#> Bootstrap type: reb0
#>
#> Number of resamples: 100
#>
#> term observed rep.mean se bias
#> 1 (Intercept) 14.1577509 14.1106714 0.69124112 -0.047079508
#> 2 mathAge8 0.6388895 0.6428107 0.02426523 0.003921188
#> 3 genderM -0.3571922 -0.4043930 0.31541703 -0.047200785
#> 4 classnonmanual 0.7200815 0.6974058 0.36313295 -0.022675666
#>
#> There were 0 messages, 0 warnings, and 0 errors.
print(lme_reb_boot2, ci = TRUE)
#> Bootstrap type: reb2
#>
#> Number of resamples: 100
#>
#> term observed rep.mean se bias
#> 1 beta.(Intercept) 14.1577509 14.1577509 0.70226613 0
#> 2 beta.mathAge8 0.6388895 0.6388895 0.02365635 0
#> 3 beta.genderM -0.3571922 -0.3571922 0.37083771 0
#> 4 beta.classnonmanual 0.7200815 0.7200815 0.39690862 0
#> 5 vc.(Intercept) 3.3122380 3.3122380 0.88196472 0
#> 6 vc2 19.7280582 19.7280582 1.31218455 0
#>
#> There were 0 messages, 0 warnings, and 0 errors.
#> # A tibble: 18 × 6
#> term estimate lower upper type level
#> <chr> <dbl> <dbl> <dbl> <chr> <dbl>
#> 1 beta.(Intercept) 14.2 12.8 15.5 norm 0.95
#> 2 beta.mathAge8 0.639 0.593 0.685 norm 0.95
#> 3 beta.genderM -0.357 -1.08 0.370 norm 0.95
#> 4 beta.classnonmanual 0.720 -0.0578 1.50 norm 0.95
#> 5 vc.(Intercept) 3.31 1.58 5.04 norm 0.95
#> 6 vc2 19.7 17.2 22.3 norm 0.95
#> 7 beta.(Intercept) 14.2 12.8 15.6 basic 0.95
#> 8 beta.mathAge8 0.639 0.592 0.684 basic 0.95
#> 9 beta.genderM -0.357 -1.18 0.302 basic 0.95
#> 10 beta.classnonmanual 0.720 -0.0567 1.45 basic 0.95
#> 11 vc.(Intercept) 3.31 1.59 4.88 basic 0.95
#> 12 vc2 19.7 17.2 21.9 basic 0.95
#> 13 beta.(Intercept) 14.2 12.7 15.5 perc 0.95
#> 14 beta.mathAge8 0.639 0.594 0.686 perc 0.95
#> 15 beta.genderM -0.357 -1.02 0.466 perc 0.95
#> 16 beta.classnonmanual 0.720 -0.00994 1.50 perc 0.95
#> 17 vc.(Intercept) 3.31 1.75 5.04 perc 0.95
#> 18 vc2 19.7 17.5 22.2 perc 0.95
The confint() Function
Similarly, the syntax of the confint() function resembles the default. The object for which confidence are calculated must be the lmeresamp object returned by the bootstrap() call. The type of confidence interval may be specified with type, for which possible values include: "basic" (basic bootstrap interval), "norm" (normal bootstrap interval), "perc" (percentile bootstrap interval), and "all" (all of aforementioned methods, and the default if method is unspecified). The level at which the confidence interval is to be computed may be specified with level, which defaults to 0.95 if unspecified.
Examples
# all ci types, 0.95 confidence level
confint(lme_reb_boot2)
#> # A tibble: 18 × 6
#> term estimate lower upper type level
#> <chr> <dbl> <dbl> <dbl> <chr> <dbl>
#> 1 beta.(Intercept) 14.2 12.8 15.5 norm 0.95
#> 2 beta.mathAge8 0.639 0.593 0.685 norm 0.95
#> 3 beta.genderM -0.357 -1.08 0.370 norm 0.95
#> 4 beta.classnonmanual 0.720 -0.0578 1.50 norm 0.95
#> 5 vc.(Intercept) 3.31 1.58 5.04 norm 0.95
#> 6 vc2 19.7 17.2 22.3 norm 0.95
#> 7 beta.(Intercept) 14.2 12.8 15.6 basic 0.95
#> 8 beta.mathAge8 0.639 0.592 0.684 basic 0.95
#> 9 beta.genderM -0.357 -1.18 0.302 basic 0.95
#> 10 beta.classnonmanual 0.720 -0.0567 1.45 basic 0.95
#> 11 vc.(Intercept) 3.31 1.59 4.88 basic 0.95
#> 12 vc2 19.7 17.2 21.9 basic 0.95
#> 13 beta.(Intercept) 14.2 12.7 15.5 perc 0.95
#> 14 beta.mathAge8 0.639 0.594 0.686 perc 0.95
#> 15 beta.genderM -0.357 -1.02 0.466 perc 0.95
#> 16 beta.classnonmanual 0.720 -0.00994 1.50 perc 0.95
#> 17 vc.(Intercept) 3.31 1.75 5.04 perc 0.95
#> 18 vc2 19.7 17.5 22.2 perc 0.95
# 90% percentile bootstrap intervals
confint(lmer_reb_boot0, method = "perc", level= 0.90)
#> # A tibble: 12 × 6
#> term estimate lower upper type level
#> <chr> <dbl> <dbl> <dbl> <chr> <dbl>
#> 1 (Intercept) 14.2 13.1 15.3 norm 0.9
#> 2 mathAge8 0.639 0.595 0.675 norm 0.9
#> 3 genderM -0.357 -0.829 0.209 norm 0.9
#> 4 classnonmanual 0.720 0.145 1.34 norm 0.9
#> 5 (Intercept) 14.2 13.1 15.3 basic 0.9
#> 6 mathAge8 0.639 0.599 0.674 basic 0.9
#> 7 genderM -0.357 -0.915 0.146 basic 0.9
#> 8 classnonmanual 0.720 0.237 1.33 basic 0.9
#> 9 (Intercept) 14.2 13.0 15.2 perc 0.9
#> 10 mathAge8 0.639 0.604 0.679 perc 0.9
#> 11 genderM -0.357 -0.861 0.201 perc 0.9
#> 12 classnonmanual 0.720 0.113 1.20 perc 0.9
The plot() function
Finally, the plot() function creates a density plot of bootstrap estimates for a default (the first bootstrap statistic, often the intercept) or specified parameter. The bottom of the graph also contains 66% and 95% percentile intervals for the covariate.
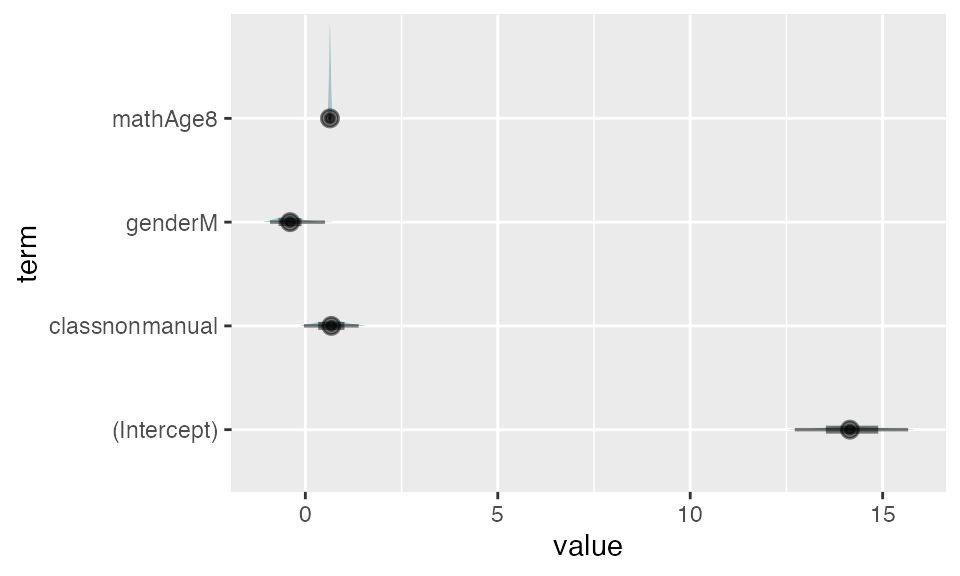
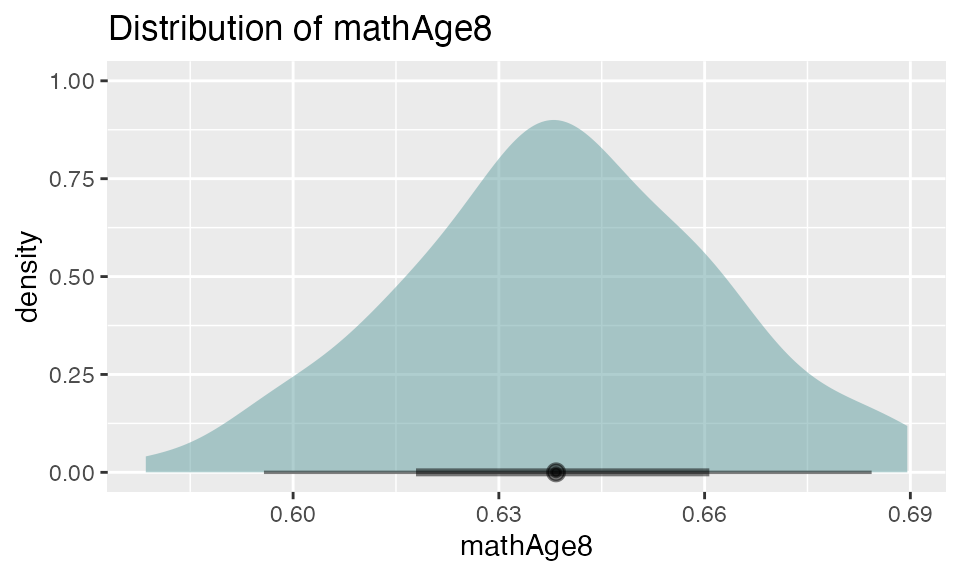
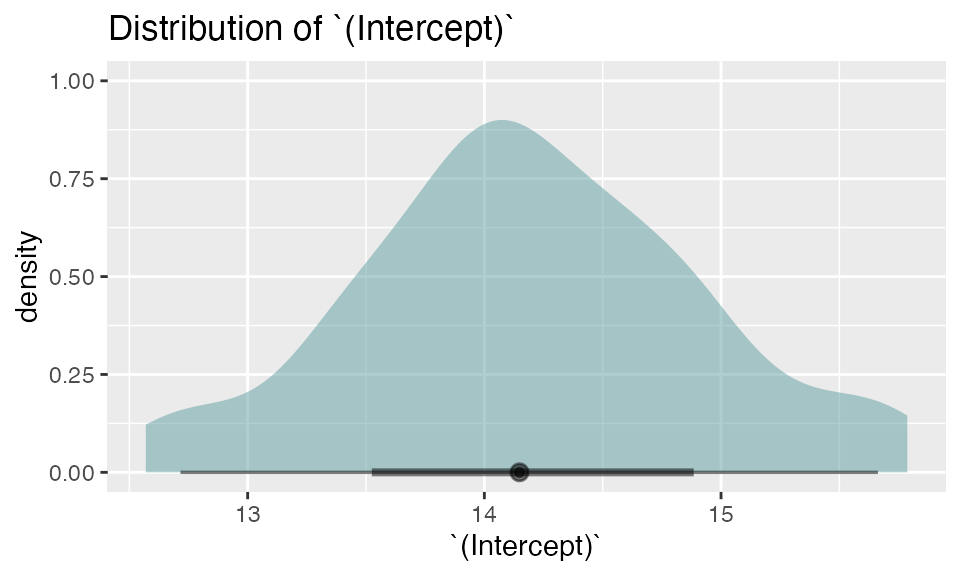
7. Bootstrapping with GLMMs
It is also possible to perform bootstraps on generalized linear mixed models (GLMMs), or hierarchical generalized linear models. In lmeresampler, GLMMs are compatible with the parametric, cases, and residual bootstraps.
8. Parallelization (User Extension)
The Idea
Parallelization (also known as parallel computing, parallel processing, or executing “in parallel”) is the idea of splitting a process into sub-processes that execute at the same time. This is of interest in the context of bootstrapping because bootstrapping is often both computation-heavy and time-consuming.
Using parallelization, the processes behind bootstrap() can be executed on multiple computer cores, depending on the makeup of the machine you are using. To check how many cores your machine has, run parallel::detectCores(). This will output the number of cores your CPU “logically” has, which is twice more than the number of cores it physically has. The number of logical cores is the number of cores you may actually use when working in parallel (the more cores you have available to you, the better!). We recommend using multiple cores when possible, without using all/most of your CPU’s cores, which it needs to run everything, not just your IDE (e.g., RStudio). However, if your machine only has one core, parallelization is neither useful nor possible.
Performance
It is important to note that while the number of cores used with parallelization will be some scalar multiple of the default number of one core used for non-parallel processing, the runtime of parallel processes will not be increased by that same scalar. That is, running a process on two cores does not yield a runtime that is twice as fast as running the same process on one core. This is because parallelization takes some overhead to split the processes, so while runtime will substantially improve, it will not correspond exactly to the number of cores being used.
There are two types of parallelization techniques: forking (also known as multicore) and clustering. While forking tends to be slightly faster, it cannot be executed on Windows operating systems; thus, we will spend our time documenting clustering, which is system-agnostic. For more information on how to use forking with parallelization, check out the parallel package.
Implementation
We implement our parallel processing using Steve Weston and Rich Calaway’s guide on jointly using doParallel and foreach, as the code is both concise and simple enough for those without much experience with parallelization. While doParallel and foreach default to multicore (forking) functionality when using parallel computing on UNIX operating systems and snow (clustering) functionality on Windows systems, in order to be as explicit as possible, we will outline our examples using clustering. For more information on forking, please see Weston and Calaway’s guide, “Getting Started with doParallel and foreach”.
The basic idea with clusters is that they execute tasks as a “cluster” of computers, which means that each cluster needs to be fed in information separately. For this reason, clustering has more overhead than forking. Both doParallel and foreach use what Weston and Calaway call “snow-like functionality”, meaning that while the clustering is done using these two packages, it uses the syntax from snow (a now deprecated package). Clusters also need to be “made” and “stopped” with each call to a foreach() loop and doParallel, to explicitly tell the CPU when to begin and end the parallelization.
Examples
With all of this in mind, let’s explore an example using lmeresampler. Notice that we have the user implement the parallelization with the bootstrap() call itself, rather than doing it within lmeresampler itself. Thus, a modified, parallelized, call to bootstrap() is as follows:
library(purrr)
library(foreach)
library(doParallel)
set.seed(1234)
numCores <- 2
cl <- makeCluster(numCores, type = "PSOCK") # make a socket cluster
doParallel::registerDoParallel(cl) # how the CPU knows to run in parallel
clusterCall(cl, function(x) .libPaths(x), .libPaths())
#> [[1]]
#> [1] "/private/var/folders/p0/kzl82ys143d1wd2kfj24jm_8000pww/T/RtmpVRsEB5/temp_libpathe7816248d8c"
#> [2] "/Library/Frameworks/R.framework/Versions/4.1/Resources/library"
#>
#> [[2]]
#> [1] "/private/var/folders/p0/kzl82ys143d1wd2kfj24jm_8000pww/T/RtmpVRsEB5/temp_libpathe7816248d8c"
#> [2] "/Library/Frameworks/R.framework/Versions/4.1/Resources/library"
b_parallel2 <- foreach(B = rep(250, 2),
.combine = combine_lmeresamp,
.packages = c("lmeresampler", "lme4")) %dopar% {
bootstrap(vcmodA, .f = fixef, type = "parametric", B = B)
}
stopCluster(cl)Let’s compare the runtime of the above b_parallel2 with the same bootstrap run without parallelization. Note that differences in runtime will be somewhat arbitrary for a small number of resamples (say, 100), and will become more pronounced as the number of resamples increases (to 1000, for example), in favor of the parallelized bootstrap.
system.time(b_nopar <- bootstrap(vcmodA, .f = fixef, type = "parametric", B = 5000))
#> user system elapsed
#> 51.097 0.300 51.666
numCores <- 2
cl <- makeCluster(numCores, type = "PSOCK")
doParallel::registerDoParallel(cl)
clusterCall(cl, function(x) .libPaths(x), .libPaths())
#> [[1]]
#> [1] "/private/var/folders/p0/kzl82ys143d1wd2kfj24jm_8000pww/T/RtmpVRsEB5/temp_libpathe7816248d8c"
#> [2] "/Library/Frameworks/R.framework/Versions/4.1/Resources/library"
#>
#> [[2]]
#> [1] "/private/var/folders/p0/kzl82ys143d1wd2kfj24jm_8000pww/T/RtmpVRsEB5/temp_libpathe7816248d8c"
#> [2] "/Library/Frameworks/R.framework/Versions/4.1/Resources/library"
system.time({
b_parallel2 <- foreach(B = rep(2500, 2),
.combine = combine_lmeresamp,
.packages = c("lmeresampler", "lme4", "purrr", "dplyr")) %dopar% {
bootstrap(vcmodA, .f = fixef, type = "parametric", B = B)
}
})
#> user system elapsed
#> 0.062 0.009 31.956
stopCluster(cl) Pretty useful stuff! The above can be applied to all bootstrap types and models fit using both lme4 and nlme.
9. Future Directions (Developer Extensions)
When fitting linear mixed effects models, it is common that users need to use data with crossed effects, that is, when lower-level observations exist in multiple factors of a higher-level. For example, if patients (level-1) adhere strictly to one doctor (level-2), but the doctors work for multiple hospitals (level-3), levels two and three are crossed. It is currently possible to use lmeresampler to bootstrap a model with crossed effects with the parametric bootstrap, however, future updates should explore adding functionality to allow bootstrapping of crossed models for the cases, residual, wild, and REB bootstraps. Crossed relationships need to be evaluated differently than standard nested relationships, thus the code will need significant modifications in its evaluation process.
References
Carpenter, J.R., Goldstein, H. and Rasbash, J. (2003), A novel bootstrap procedure for assessing the relationship between class size and achievement. Journal of the Royal Statistical Society: Series C (Applied Statistics), 52: 431-443. DOI: 10.1111/1467-9876.00415
Leeden R.., Meijer E., Busing F.M. (2008) Resampling Multilevel Models. In: Leeuw J.., Meijer E. (eds) Handbook of Multilevel Analysis. Springer, New York, NY. DOI: 10.1007/978-0-387-73186-5_11
Modugno, Lucia and Giannerini, Simone, “The Wild Bootstrap for Multilevel Models,” Communications in Statistics — Theory and Methods 44, no. 22 (2015): 4812–25, https://doi.org/10.1080/03610926.2013.802807
Raymond Chambers & Hukum Chandra (2013) A Random Effect Block Bootstrap for Clustered Data, Journal of Computational and Graphical Statistics, 22:2, 452-470, DOI: 10.1080/10618600.2012.681216
Microsoft Corporation and Steve Weston (2020). doParallel: Foreach Parallel Adaptor for the ‘parallel’ Package. R package version 1.0.16.
Roodman, D., Nielsen, M. Ø., MacKinnon, J. G., & Webb, M. D. (2019). Fast and wild: Bootstrap inference in Stata using boottest. The Stata Journal, 19(1), 4–60.